- Why Surface RT failed and iPad didn’t (NYT)
- A telling lesson on why too many options is not necessarily a good thing
- Tiny lasers will speed up future computers (ars)
- Apple TV: Cooperating with content providers (NYT)
- Economics 101: Killing America (salon)
- Economics is not science, agree to that
- 10 mind blowing technologies that will appear by 2030 (io9)
- Why retailers ask for ZipCode when you checkout (forbes)
- Ofcourse for marketing purpose.. but can lead to unexpected consequences
- This debate never dies off
- Finance set to surpass tech as the most profitable industry (usatoday)
- Which investment is better: Hollywood or Siliconvalley (NYT)
- History of Apps pricing, why most apps are free (flurry)
- How Windows monopoly is getting destroyed (BI)
- Give me back my iPhone (slate)
Author: SK
Saravana “SK” Krishnamurthy is VP of product management at MariaDB. A Silicon Valley citizen for quarter of a century. His passion is to explain complex ideas to "muggles" without horrid and unnecessary details.
July 17, Mid-Week Readings
- PivotalHD is available for download by SK (yours faithfully) (gopivotal)
- Pivotal ships Hadoop to masses – my first appearance in The Register (TheRegister)
- Social Media bubble is deflating (BW)
- Pivotal ships Hadoop distro complete with SQL (jexenter)
- Hey engineers – Your product manager needs a hug (aha.iohttp://blog.aha.io/index.php/hey-engineers-your-product-manager-needs-a-hug/)
- Practical introduction to Data Science skills (google)
July 15, Early week Readings
- The Dropbox opportunity (link)
- Microsoft overhauls the Apple way (NYT)
- How to tell you’ve a lousy 401k (YahooFinance)
- Cars are fast becoming Smartphones on wheels (TR)
- You want to hide from NSA? Guide to nearly impossible (wired)
- Not even Hadoop is free of patent-troll attack (NYT)
- Warren: Human Bigdata engine (gooddata)
Mid-Week: Reads
Mid-Week Readings:
- Unexpected use for Enron emails – BigData! (MIT Tech Review)
- Tech spending will reach $3.7 trillion in 2013, Gartner predicts (AllthingsD)
- How Apple and IBM learned to change with times (USANews)
- The essential WallStreet summer reading list (NYT)
- What’s wrong with technology fixes (BostonReview)
- Why doesn’t Apple enable sustainable business on the AppStore (Stratechery)
- Pandora paid over $1300 not $16 for playing one million songs (Link)
- How to give a killer presentation – a story of “lion lights”. Inspiring (HBR)
Mid-Week Watch list:
- Art of choosing: Fascinating book about the choices we make. Quick intro by author (Columbia U’s Sheela Iyengar) (video)
HAWQ: The New Benchmark for SQL on Hadoop
Business data analytics has changed tremendously in recent years. When enterprise datasets consisted entirely of structured data generated from ERP, CRM and other operational databases, businesses would typically use heavyweight ETL process to load data into Enterprise Datamarts or to EDW systems.
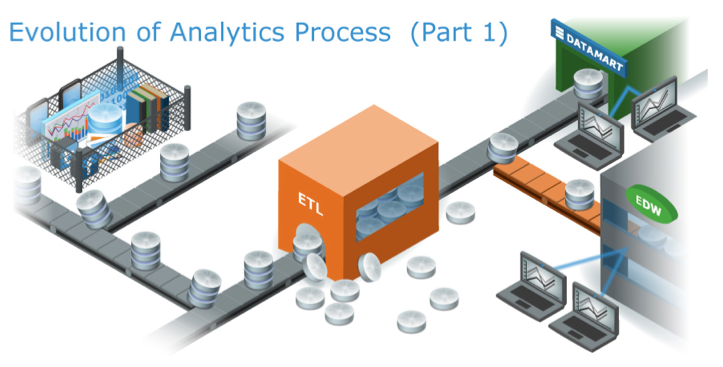
Since these systems were commonly sold as purpose-built hardware and software, they carried premium price tags — $100,000/TB was not unheard of. The high cost of storage and processing forced enterprises to carefully plan their ETL process, and what data would be stored in these systems. In the majority of these cases, unused datasets would be discarded, archived into backup systems, or put in cold storage.
Big Data Landscape
Today enterprises generate complex datasets comprised of both structured and unstructured data sourced from web content, clickstreams, and machines. It is estimated that around 80-90% of data generated in the enterprise setting is unstructured. Enterprises realize that the data generated internally and by customers is a high value asset, containing valuable information which businesses can derive strategic insights from.
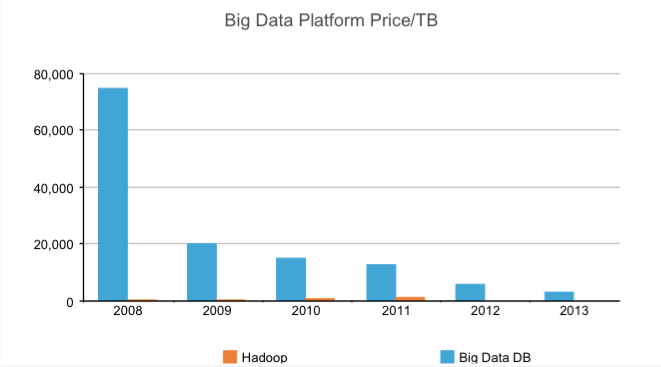
Fortunately, the introduction of Hadoop and HDFS made storing and processing huge amounts of data cheaper and more practical. As the above chart shows, the cost of storing data in Hadoop dramatically changed the economics of scaling to address data storage and processing needs. Companies no longer need to discard valuable strategic data assets. Instead, these data sets can be archived in HDFS for on-demand analysis using MapReduce.
Enterprise Big Data Reality
However, enterprises often have Data Scientists and Analysts who are highly skilled in writing complex SQL queries, or using stored procedures or pre-canned algorithms such as MADLib. In most cases, these busy employees feel compelled to learn Java and master new programming paradigms. Meanwhile, enterprises have huge existing investments in BI and visualization tools that generate complex SQL statements to analyze and present data. While Hadoop provides cheaper and distributed storage, programming paradigms such as MapReduce, Hive, and Pig may demand employees learn new languages to be immediately productive. This can be a disincentive for enterprises wishing to exploit the advantages of Hadoop.
Enterprises are eager to leverage their existing investment in people, utilize their business knowledge and, maintain their productivity, while taking advantage of Hadoop and unstructured data analytics to gain a strategic advantage. Therefore, many companies adopted a model in which HDFS is used as a cheap distributed storage solution from which specific data sets are selectively loaded into datamarts, to run BI tools on this data on-demand. This model works in most cases, but creates an operational challenge, requiring businesses to manage multiple datasets and software services which run in different clusters.
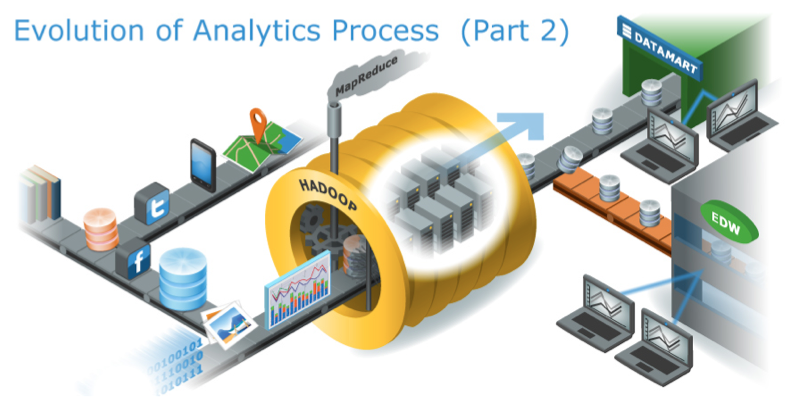
In summary, there are 4 major challenges emerge that underscores the reality facing an enterprise that wants to put big data into use:
- Reuse investment in traditional BI and visualization tools.
- Utilize existing skill sets in the organization and keep morale high without losing productivity.
- Combine structured and unstructured data in single query (ex. correlate a customer ID stored in database to customer activity in weblog to gain insights into customer activity in website).
- Take advantage of the efficient storage and powerful processing capabilities of Hadoop.
My interactions with customers made me realize that customers are making huge bets on Hadoop, and expect vendors to adopt solutions that adhere to the default standards, while providing them with a familiar toolset to maintain or improve productivity.
HAWQ Changes Everything
On Monday, February 25th we announced HAWQ, the most powerful query engine built using proven parallel database technology of Greenplum Database for analyzing massive amount of data in Hadoop using industry standard SQL constructs. HAWQ is the most complete, performant, and capable SQL engine available on the market right now. It delivers a fully-functional, high performance “True SQL” database and makes SQL a first class citizen in the Hadoop cluster. HAWQ utilizes the same technology that made Greenplum Database the dominant force in MPP database market. It brings in the innovations bought forth by Greenplum Database over the past 10+ years to optimize the MPP database to fully utilize distributed computing and query processing.
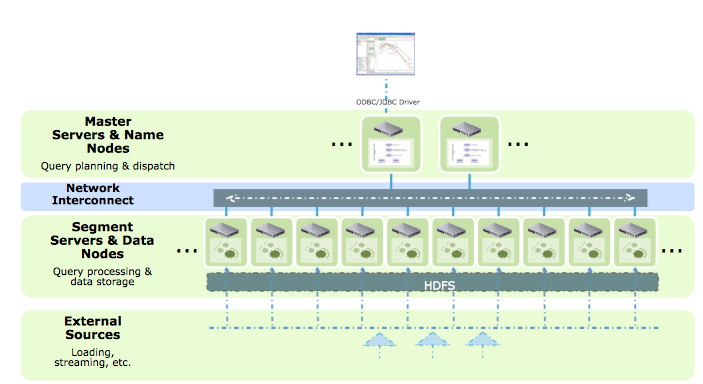
HAWQ also enables users to query data stored in flat files in HDFS, Hive, and HBase. Users can run SQL queries on data stored in Avro, ProtoBuf, Delimited Text and Sequence Files, with these queries running in parallel for maximum performance. When querying Hive and HBase, it pushes filters and predicates to the target engine, where filters can be efficiently processed. It streams out only the results set, rather than entire dataset, to the query processing engine. This greatly increases processing capability, while reducing network strain and query latency.
Why is HAWQ important?
For the first time enterprises have the ability to satisfy all the 4 use cases outlined above. HAWQ is the most functionally rich, most mature, most robust SQL offering available for Hadoop. Through Dynamic Pipelining, World Class Query Optimizer and the numerous innovations of the Greenplum Database, it provides performance that is unimaginable.
We are very excited about the possibilities HAWQ offers to Pivotal HD customers. We have had highly positive feedback from customers and partners that were part of the initial beta trials of the product. It is a transformative technology that will make an immense difference for enterprise customers frustrated with the lack of robust SQL support in the Hadoop ecosystem. In future posts, I’ll cover more features and technical details of the product. HAWQ changes everything.
\Comments
-
Mohmmed Rafi says:
Can someone tell me where the data is getting stored? Is it only getting stored in HDFS or the data is moved the Segement Servers (XFS) ? Is this GPDB on HDFS?
-
SK says:
Mohmmed,
HAWQ is essentially GPDB running in the same physical node/cluster as Hadoop. HAWQ has the same technology (optimizer, catalog, resource management, sql support etc) as GPDB and uses HDFS to store its files.
-sk
-
-
Kumar Chinnakali says:
It’s well written and image representations are immensely superb; which is crystal clear. However do we have any specific Naming sense for HAWQ. Looking deeply to have technical Blog on Pivotal HD & HAWQ.
-
Waseem Md says:
1)Can someone explain me that how the data from HDFS is accessed ? Is it that data is fetched to something called as Segments and processed in the segments, IF SO will it be first fetch data from HDFS to Segments and process in segment give back the result to the user (where the results would be stored HDFS or Segments ) or the data is processed in the HDFS itself.
2)Is update query possible in HAWQ or is it similar to Impala and Hive without the update query
3)And please share some tutorial for HAWQ commands and for how the data is processed in Pivotal HD through HAWQ.
Why SAAS may not be panacea for in-house software ills?
More and more companies are moving towards SAAS based software solutions such as salesforce.com, workday, Google Apps and even MS’s Office 365. Biggest SAAS vendors are making tons money selling their wares as cost effective solutions. But does that automatically translate to cost savings to organizations that deploy the SAAS solutions? The answer is somewhere in between. Companies need to be careful in how they are selecting their services and deploy them inside their organizations. There are plenty of comparison services out there that go into detailed review and comparison of each online services. There are legions of companies that will help you get off the ground with SAAS deployments.
Any typical software role out cannot live on its own. IT systems are so interwined within and outside organizations that they need to share data amongst themselves. CRM systems need to be integrated with email, calendar, inventory, billing, manufacturing and sales data base systems (to say the least). HR systems needs to be integrated legacy systems, packaged software and other SAAS. No single provider gives these solutions out of the box. If you visit salesforce.com’s partner eco-system you’ll realize there are partner’s and solutions for every system out there. They’ll happily help you to integrate and customize these systems for a cost.
Related articles
- Forrester says Future of Cloud is SaaS (setandbma.wordpress.com)

Got a surprise invite to Google Music
I don’t remember asking for Google Music invite. Surprisingly received an invite today and promptly signed up for it. It is obviously a competing service to iCloud and Amazon Cloud Drive, no matter how slice and dice it. Difference is, Google Music is free while the others are offered for a nominal price but with unlimited storage.
After sign up, the music service ask you to select your preferred genre of music style. To upload your songs you need need install a small piece of software. You can update up to 20,000 tracks to the service. I suppose that is more than enough to store most people’s collection (I’ve 32k tracks!). Here is a screenshot of the service:
Google Music has free selection of music that is presented to you based on the music genres you like. I’ve some free selections shown (I cannot figure out the total number of tracks in my free music playlist?).
The service is a good add-on for Google’s ChromeBook OS, as a iTunes replacement for ChromeBook. Google’s strategy does seem to evolve towards moving users to Cloud based OS, Storage and Media(refer my previous post on SageTV acquisition). However, I would like to have offline storage as well. ChromeBook’s cloud OS seem to choke my computing senses by offering just a browser. I invariably try to close that damn browser (jail) and feel choked when I cannot access my hard disk!. Why not offer a local caching option so that I don’t need to always look for internet connection to use my Laptop? Have some intelligent caching and offer users a way to access local storage for music, photos and video that they don’t want to upload to cloud?
February 27, 2013 at 4:06 am
SK,
Very well written article.. Love the images in the article.. You captured the essence of the HAWQ announcement very well. I think with HAWQ, organizations who were vary of Hadoop adaptation will come on board (even hesitantly), and that too not just because of the cost but also for the ease of use (via SQL layer)..
This makes all the Shelfware reusable again but this time with Hadoop capabilities. Looking forward to your future blogs as wel..
Ajay